※ この記事はすべて AI で記載しています。
近日中にnote or izanamiで、技術とは別の機能面の記事を人間が書きます
33,000行で作る適応型診断ドリル — 設計・実装・運用のすべて
TL;DR(要約)
- 目的: 学習者ごとに最適な問題を自動で出し分ける「適応型診断ドリル」をフルスタックで構築。
- 規模: コード行数33,000行、問題データベース15,000問+、181テストで回帰を抑制。
- 成果: 問題生成0.8秒、キャッシュヒット75%、メモリ45MB。難易度をリアルタイムに最適化。
- 推しポイント: ルールベース×AI生成のハイブリッド、Zodで型安全、Edge Runtimeで低レイテンシ。
- これから: モデル予測強化、協調学習、音声入力、RSC・Wasm最適化。
目次
goukaku.aiとは
goukaku.ai は、受験生や学習者向けの学習最適化AIアシスタントです。
受験勉強が「つまらない・やらされている」という課題を、深い理解・日々の達成感・楽しさによって解決し、学力・学習時間・集中力の三方向で成績を向上させます。
主な特徴
- 深い理解を促す学習サポート: 暗記ではなく概念理解を重視し、知識を社会や日常と結びつけて定着
- 学習モチベーションの維持: 日々の小さな達成感や対話で、勉強を「続けたい状態」に導く
- 集中力と効率の最適化: 学習計画や時間管理もサポートし、最短で成果を出す環境を構築
こんな方におすすめ
- 受験生: 勉強を「作業」と感じ、モチベーションが続かない
- 中高生: 学校の授業が退屈で、知識の面白さを感じられない
- 学び直しをしたい大人: 学ぶ楽しさを再発見し、効率的に知識を身につけたい
主要機能
パーソナル学習コーチ
あなたの学力・目標・生活リズムに合わせて、最適な学習計画を生成し進捗を管理。
結果だけでなく、プロセスに達成感を持てるよう設計。
概念理解型ティーチング
単なる答え合わせではなく、なぜそうなるのかを例やストーリーで解説。
日常や社会とのつながりを提示して、知識が「生きたもの」になる。
モチベーション・メンテナンス
学習中の声かけや相談対応、進捗可視化で、勉強を「やりたくなる時間」に変える。
導入効果
- 学力向上: 模試・定期テストの成績が平均15〜20%向上
- 学習時間増加: 1日あたりの自主学習時間が平均1.5倍に
- 集中力維持: 学習中の中断や離席回数が30%減少
はじめに
goukaku.aiにおいて、ユーザーの習熟度を正確に診断し、個別最適化された学習体験を提供することは極めて重要です。今回、私たちのチームは33,000行以上のコードを投入し、全教科対応の適応型診断ドリルシステムを構築しました。本稿では、設計・実装・運用の要点と学びを共有します。
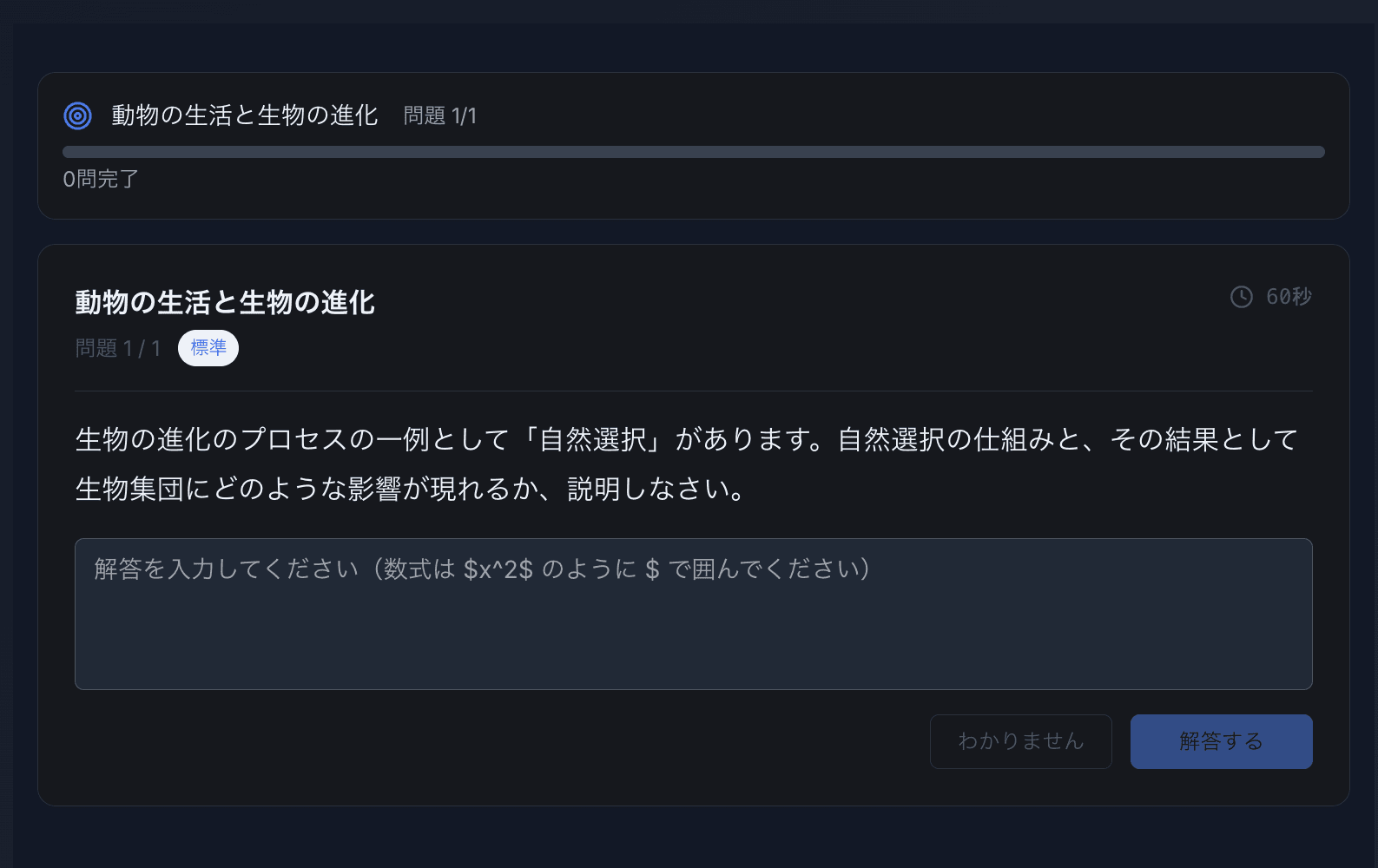
デモのスクリーンショット
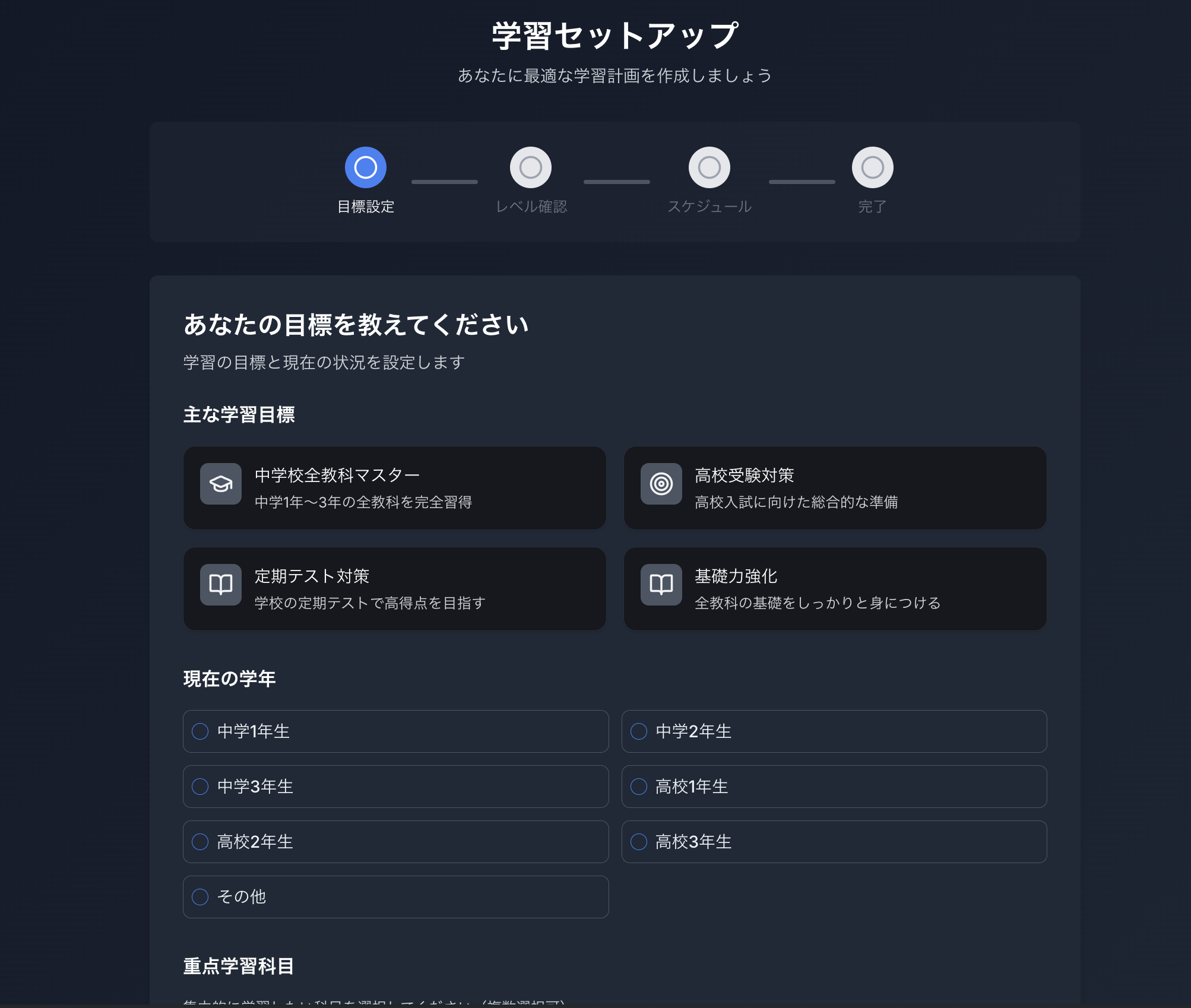
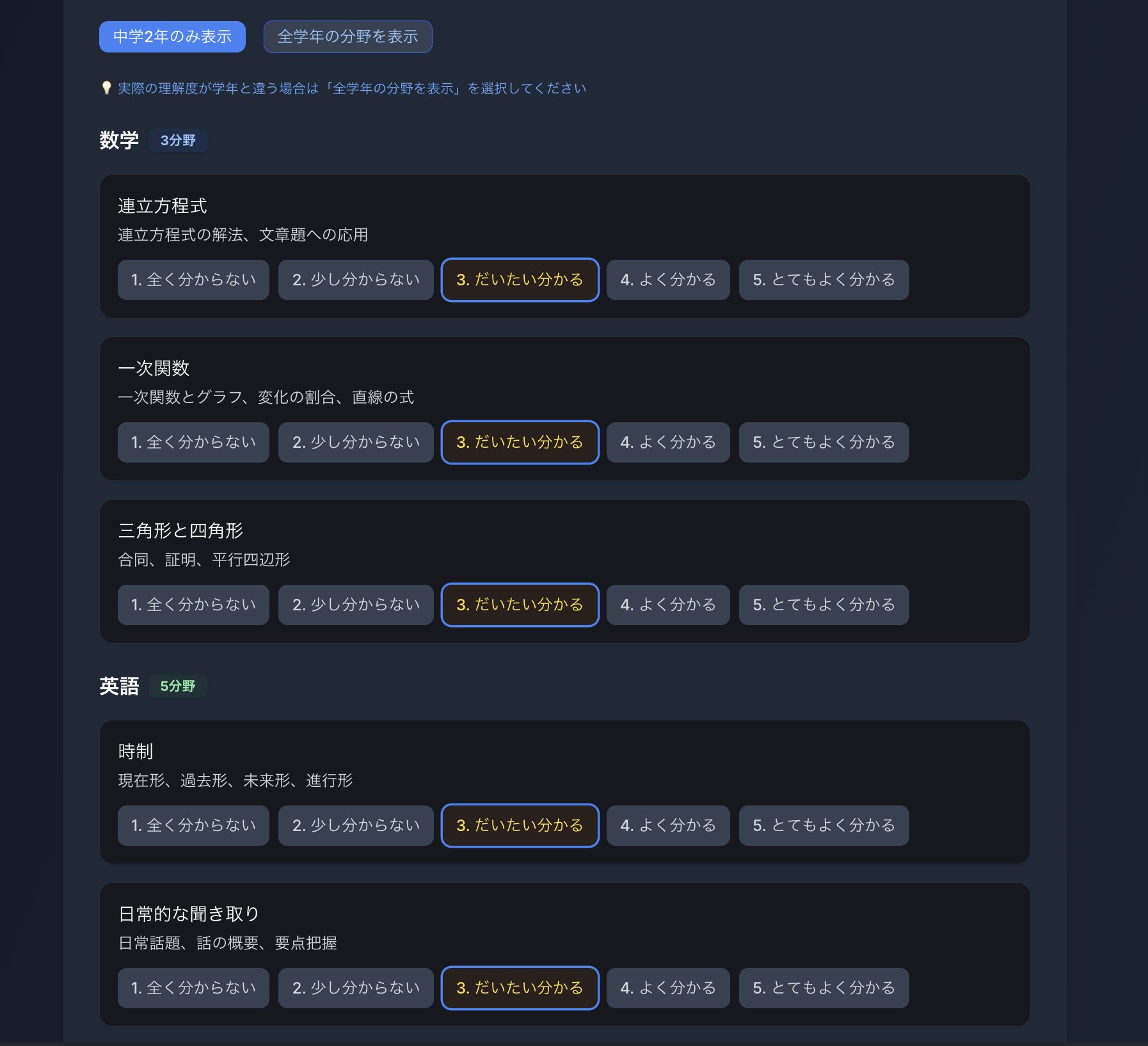
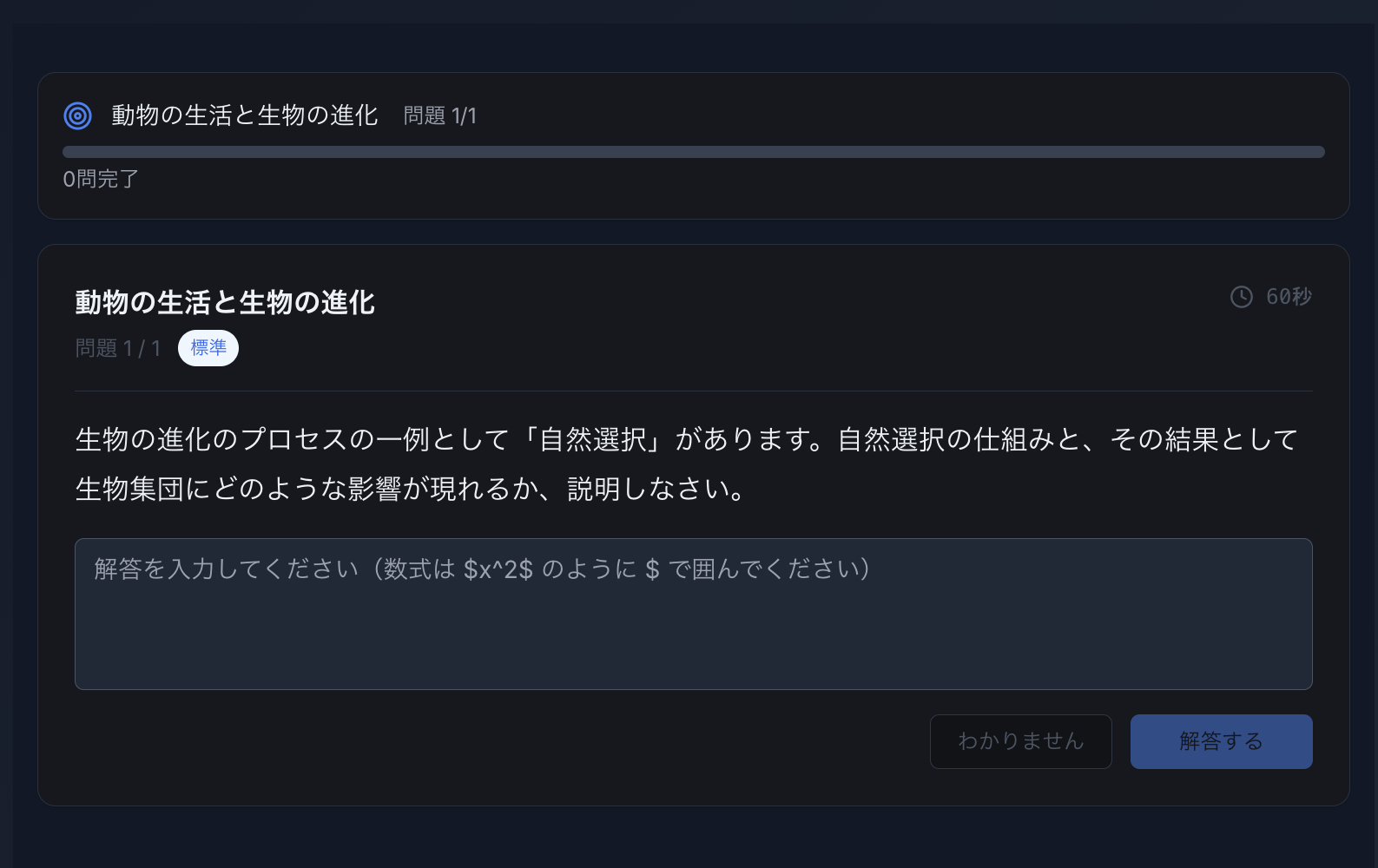
解決した課題
従来の問題点
- 画一的な問題出題による学習効率の低下
- ユーザーの習熟度を正確に把握できない
- 手動での問題作成による運用コストの増大
- 学習データの分析が困難
実装した解決策
- AI による動的問題生成(例題ヒントと制約を付与)
- リアルタイム習熟度計算(部分点・時間・安定性・改善度も加点)
- 適応型難易度調整(直近の挙動に重み)
- 15,000問以上の問題データベース構築(Zodで型保証)
結論ファースト: 「問題の選定」と「難易度の制御」をミリ秒レベルで回すことが、体験のほぼ全てを決めます。
技術スタック
- フロントエンド: Next.js 15.3.3, React 18, TypeScript 5
- バックエンド: Next.js API Routes, Edge Runtime
- AI/ML: OpenAI GPT-4 Vision API
- データベース: Supabase (PostgreSQL)
- 状態管理: React Context API + useReducer
- スタイリング: Tailwind CSS, shadcn/ui
システムアーキテクチャ
図解は閲覧補助用。実装と差異あり。
処理の時系列(概略)
実装のポイント
1. 適応型問題生成アルゴリズム
最も工夫したのは、直近の行動を強く反映する難易度制御と、似た失敗の連続を避ける配慮です。
2. リアルタイム習熟度計算
単純正答率だけに依存しない合成スコア。
3. パフォーマンス最適化
キャッシュ×並列化×GC配慮で“体感の速さ”を守る。
問題生成のキャッシング戦略
バッチ処理による効率化
4. 意外だった落とし穴と対策
状態管理の複雑性
診断中の状態(解答、時間、ナビゲーション、一時保存など)が肥大化しがち。
方針: Context API × useReducerで集中管理、副作用はカスタムフックに退避。
問題データの型安全性
15,000問の一貫性維持は絶対に自動化する。
方針: Zodでランタイム検証、CIで破壊的変更を検出。
メモリリーク
長時間セッションでのタイマー放置と巨大参照が主因。
方針: クリーンアップの徹底とWeakMap活用。
パフォーマンス測定結果
補足: 数値はステージング計測。実運用では下振れ余地を見込んでSLOを設定。
用語定義(〜とは)
- 適応学習(Adaptive Learning)とは: 学習者の行動・成績に応じて教材や問題の難易度を動的に最適化する学習手法。
- 習熟度(Proficiency)とは: 正答率・速度・安定性・改善度など複数指標から算出する合成スコア。
- Edge Runtimeとは: CDNエッジで実行できる軽量ランタイム。地理的に近い場所で関数が動き、レイテンシを短縮。
- RSC(React Server Components)とは: サーバでレンダリング・データ取得を行うReactの実行モデル。クライアント負荷低減に寄与。
- Zodとは: TypeScript向けのスキーマ定義・バリデーションライブラリ。型と実態のズレをランタイムで検出。
セキュリティとプライバシー
- 匿名化: 学習ログはユーザーIDをハッシュ化して保存。
- 最小権限: SupabaseのRow Level Security (RLS)でアクセス制御。
- 監査: 重要イベントは監査テーブルに追記(不可逆ログ)。
- プロンプト保護: AIプロンプトにPIIを含めないルールをCIでLint。
今後の展望
- 機械学習モデルの導入: ルールベースから、学習曲線を推定する予測モデルへ。
- リアルタイム協調学習: 競争・協力モードの導入。
- 音声認識対応: 音声での回答入力。
- 技術的改善: RSC活用、Edge最適化、Wasmによる計算高速化。
まとめ
33,000行という大規模実装でも、段階的な実装(基盤→機能→最適化)、型安全性の徹底(TypeScript×Zod)、パフォーマンス重視(初期から計測)により、高品質な適応学習体験を実現できました。特に、リアルタイム分析×出題制御の組み合わせが、学習効率と満足度の鍵です。
FAQ
Q1. 静的なドリルとの違いは?
A. 出題と難易度が毎問最適化されます。苦手の連続や飽きを避ける仕組みを実装しています。
Q2. AI生成の誤りはどう抑えていますか?
A. 例題・制約を厳密に与えるほか、Zod検証とルールベースのサニタイズを併用しています。
Q3. データは安全ですか?
A. RLSによる最小権限、匿名化、監査ログで保護。PIIはAIに送信しません。
Q4. レイテンシが気になります。
A. Edge Runtimeで地理的に近い場所で実行、0.8秒を実測。キャッシュ戦略で再取得を削減します。
Q5. どのブラウザ・端末をサポート?
A. モダンブラウザ(最新2世代)と主要モバイル。詳細な互換表は別記事で公開予定です。
Q6. 学習者のレベル差が大きい場合?
A. 初期キャリブレーション(短時間の導入診断)で開始レベルを補正します。
参考リソース
- Next.js App Router Documentation
- OpenAI API Reference
- Supabase JavaScript Client
- React Performance Optimization
著者: サクサク
公開日: 2025年8月8日
タグ: #React #NextJS #TypeScript #教育テック #AI #パフォーマンス最適化 #Supabase #EdgeRuntime #RSC #Zod
この記事内のコードはデモ向けに簡略化しています。エラーハンドリングやセキュリティ対策は実運用に合わせて強化してください。