
この記事を読むと分かること
結論
- openai の web-search api の精度はまだまだ
- search x browser の重要性
- 自力で web 探索を実装する方法や課題
どういった機能を作りたかったのか
- web 検索: キーワード検索
- ページ探索: ページを探索して必要なデータを探す
- LLM に組み込む: AI エージェントのワークフローに上記を組み込む
Tavily
Tavily とは
- web 検索: web のキーワード検索をしてくれる api です。
- 無料枠: 月々1,000リクエストまでなら無料です。神。
- mcp: mcp も提供されています。mastra を使って簡単にエージェントができる。
実装
Tavily x Mastra の簡単な実装です。
Tavliy x Mastra エージェントを使ってみた
- 質問: 企業コード1301、極洋の最新の決算成績を教えて
- 回答: データが見つかりません or 嘘数値
- 結論: 使い物にならないレベル
OpenAI の WebSearch
こちらも同様に使い物にならないレベルでした。
ChatGPT との違いは何?
ChatGPT に質問した場合
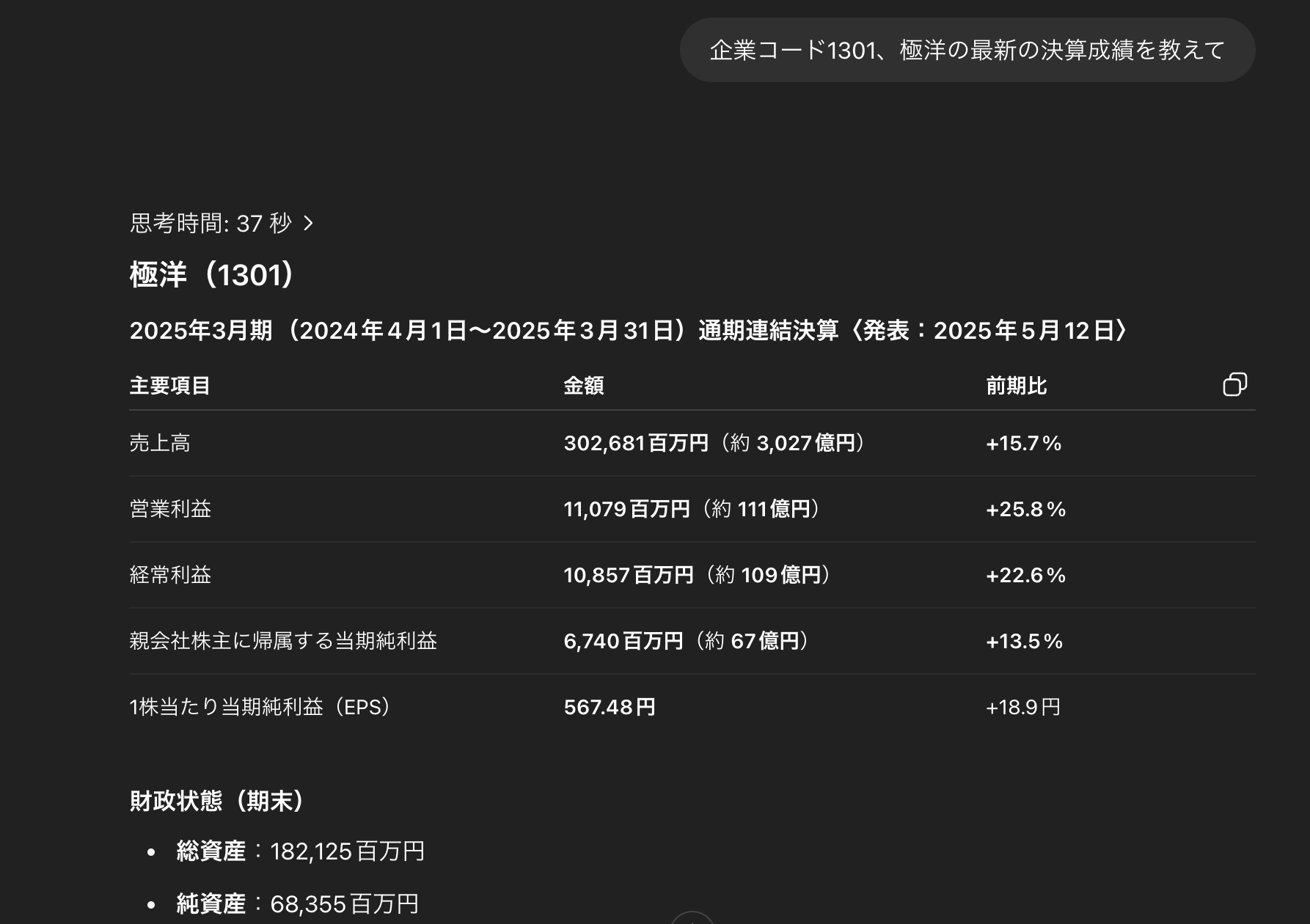
ご覧の通り、ChatGPT は正確に回答してきます。凄すぎる。どうなってんだ。
私の考え
ここらは、想像の範囲を出ないので責任は取れないですが、ChatGPT では、web 検索以外にもおそらく、ブラウザ操作系のツールが組み込まれていると思います。
| ツール | コンテンツ | 検索 | 画面操作(遷移) |
|---|---|---|---|
| Tavily x Mastra | ⚪︎ | ⚪︎ | x |
| Openai Web Search | ⚪︎ | ⚪︎ | x |
| ChatGPT | ⚪︎ | ⚪︎ | ⚪︎ |
| ブラウザ操作ツール | ⚪︎ | x | ⚪︎ |
エージェントにブラウザ操作ツールをつけると
- ナイーブな解決: playwright や puppeteer のようなツールを mcp にして使う。playwright はmcp公開されています。無料です。
- 試してみた
私が実際に playwright を試してみたのですが、以下のような問題が起こりました。 - リンクの fetch ができない: 今回 pdf をダウンロードしたかったのですが、リンクを取らせようとしても失敗することが多い
- 画面遷移がひどい: 画面遷移でループしたり、全然関係のないページに飛んだり、諦めたりすることが多かった
- pdf viewer 非対応: pdf viewer は html の構造が少し特殊で、それが原因で pdf viewer は playwright だと、viewer 画面にいった時点で動かなくなります。
- html 決算ページにはまる: html 形式で決算を公開している web ページだとそこで、ゴールだと勘違いして終了します。
他にもあげたらキリがないですが、これだけの課題がありました。
解決策
正直諦めかけていましたが、色々試行錯誤した結果、しっかりとした動作をさせることができました。以下の手順で実装を試みました。
- html ビルド用のブラウザインスタンスを使用:最初は url を fetch する実装にしていましたが、javascrpt が動くような動的な web ページでは、hydration 前の空の html が送られるだけで、web ページによっては使えなかったりするので、最終的には、javascript を含めたレンダリングができるブラウザインスタンスを使用しました。
- AWS Batch に切り替え:先日投稿した AWS 課金の記事に関連しますが、Amplify だと MCP を stdio 経由で建てることも、http 形式で活用することも難しく、batch の ec2上で動かすことが最適でした。
- html の整形:html にはさまざまなスクリプトなどのタグが含まれており、それが LLM のコンテキストにのると、コンテキストウィンドウを圧迫します。そういったデータをクリーニングする必要がありました。
- html2markdown:その後、LLM が読みやすいように、マークダウン形式に html をマッピングしました。検証段階では、a タグを引っ張ってきて LLM に与えていましたが、そうすると画面全体のコンテキストが失われて精度がイマイチなケースがあったので(それでも十分の性能ではあったが)、コンテキストを失わないような工夫をしました。
- LLM を使って、url 取得(tavily)と1〜4の操作を実行し、目的の pdf を取得するまでに至りました。結果として AI 投資ツール KabuScan の AI スクリーニングが実現できました!!!!
まとめ
というわけで、今回は KabuScan 実装時に詰まった部分の紹介をしました。面白い、ためになると感じられたら「いいね」やフォローをお願いします!X もやっていますので、よろしくお願いします!
もし、実装など詳しく知りたい方などいましたら、お気軽に連絡相談いただけたら!