
前の記事では、スクラッチから始め、FastAPIを使用してフォーラムのプロトタイプを迅速に構築しました。機能は基本的でしたが、投稿とスレッドの表示というフォーラムのコア機能はすでに備わっていました。
このプロトタイプには、1つの重大な問題があります。インメモリデータベースとしてPythonリストを使用しました。これは、サーバーが再起動するたびに、ユーザーが公開したすべての投稿が消えてしまうことを意味します。
この問題を解決するために、この記事では、フォーラムに実際のデータベースであるPostgreSQLを導入し、SQLAlchemy ORMを介して操作することで、永続的なデータストレージを実現します。
始めましょう!
PostgreSQLの準備
チュートリアルを開始する前に、PostgreSQLデータベースを準備しておく必要があります。ローカルにインストールすることもできます。手順は公式PostgreSQLウェブサイトにあります。
より簡単な代替案として、Leapcellを使用して、ワンクリックで無料のオンラインデータベースを取得できます。

ウェブサイトでアカウントを登録した後、「データベースの作成」をクリックします。4
データベース名を入力し、デプロイリージョンを選択すると、PostgreSQLデータベースが作成できます。
表示される新しいページで、データベースに接続するために必要な情報が表示されます。下部にはコントロールパネルがあり、ウェブページ上で直接データベースを読み取ったり変更したりできます。
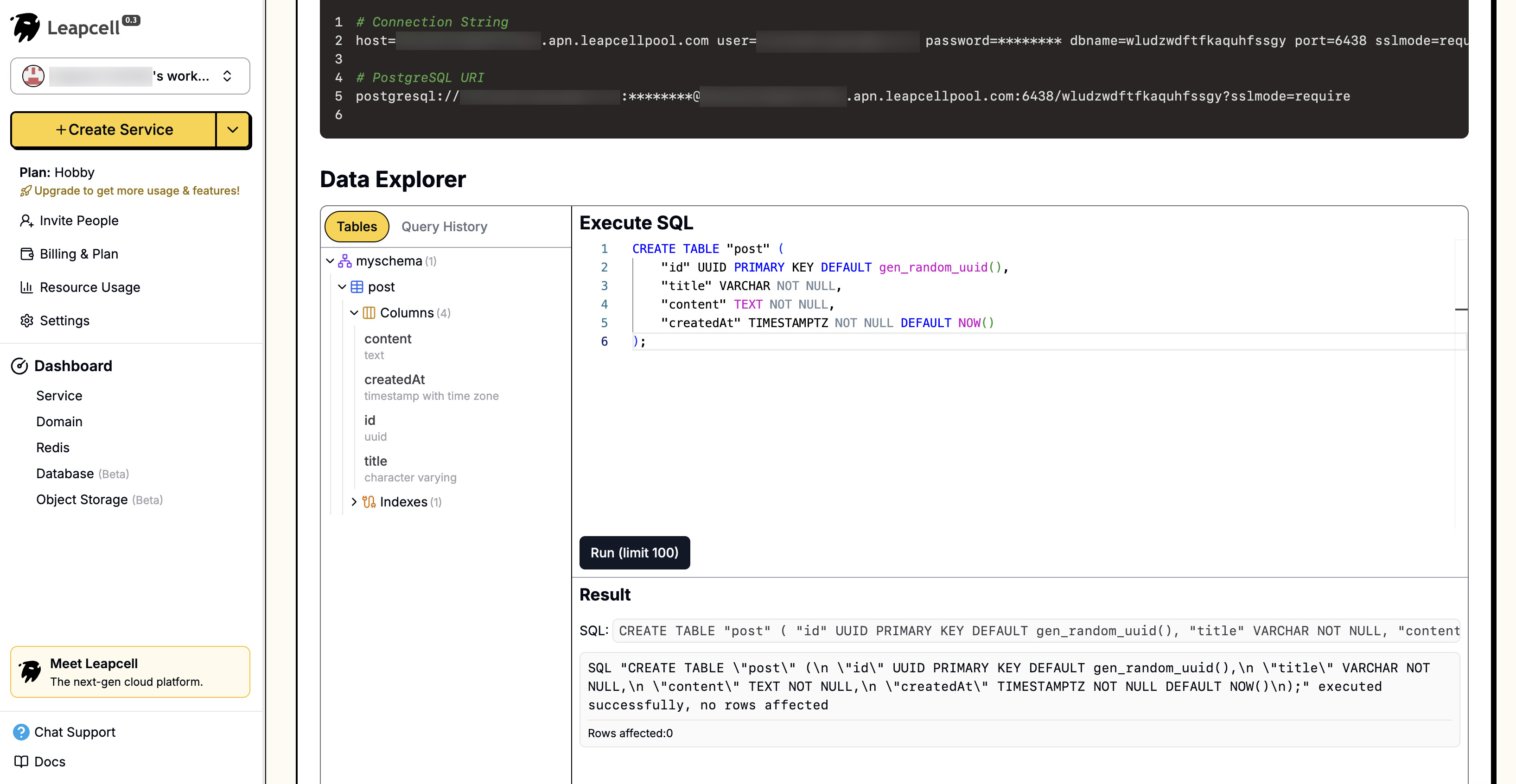
この接続情報を使用すると、追加のローカル構成なしで、さまざまなツールからデータベースに直接アクセスできます。
ステップ1:新しい依存関係のインストール
PythonがPostgreSQLと通信できるようにするには、いくつかの新しいライブラリが必要です。仮想環境がアクティブであることを確認し、次のコマンドを実行します。
sqlalchemyはPythonエコシステムで最も人気のあるオブジェクトリレーショナルマッパー(ORM)ツールです。これにより、煩雑なSQLステートメントを作成する代わりに、Pythonコードを使用してデータベースを操作できます。
psycopg[binary]は、PostgreSQLとPythonを接続するために使用されます。SQLAlchemyはこれを使用してデータベースと通信します。
ステップ2:データベース接続の確立
データベース接続関連の設定をすべて処理するために、database.pyという新しいファイルを作成します。
database.py
create_async_engineは、データベースとの通信のコアとなるSQLAlchemyエンジンを作成します。SessionLocalは、データベース操作(作成、読み取り、更新、削除)を実行するために使用されます。Baseクラスは、このチュートリアルで使用するすべてのデータベースモデル(データテーブル)の基本クラスになります。
ステップ3:データテーブルモデルの定義
これで、メモリをデータベースとして使用する必要はなくなりました。データベース内のpostsテーブルの構造を実際に定義するSQLAlchemyモデルを作成しましょう。
models.pyという新しいファイルを作成します。
models.py
このPostクラスは、postsテーブルの構造に直接対応します。
__tablename__ = "posts":データベースに対応するテーブル名を指定します。id:整数型の主キーで、クエリを高速化するためにインデックスが作成されます。titleとcontent:文字列型のフィールドです。
モデルを定義しただけでは、テーブルがデータベースにすでに存在することを意味するわけではありません。このテーブルを手動で作成するには、SQLなどのコマンドを実行する必要があります。
対応するSQLは次のとおりです。
Leapcellでデータベースを作成した場合、そのウェブページで直接SQLを入力してデータベースを変更できます。
ステップ4:APIのデータベース利用のためにリファクタリング
これが最も重要なステップです。インメモリのdbリストを完全に削除し、APIルート関数をSQLAlchemyセッションを介してPostgreSQLとやり取りするように変更する必要があります。
まず、database.pyに依存関係関数を追加します。
database.py(関数追加)
これで、APIパス操作関数でDepends(get_db)を使用してデータベースセッションを取得できます。
以下は、データベースの使用に完全に切り替わったmain.pyの最終的な完全版です。
main.py(最終完全版)
上記の手順により、以下が達成されました。
- インメモリ
dbリストが削除されました。 - データベースとやり取りするすべてのルート関数は
async defに変更され、データベース操作の前にawaitが使用されるようになりました。これは、非同期データベースドライバーとエンジンを選択したためです。 GET /postsとPOST /api/postsは、データベースからの読み取りとデータベースへの書き込みを行うように変更されました。
実行と検証
次に、uvicornサーバーを再起動します。
ブラウザを開き、http://127.0.0.1:8000にアクセスします。投稿のリストは空(データベースは新品であるため)で表示されます。
いくつかの新しい投稿を公開してみてください。以前と同じように表示されます。
次に、データ永続性をテストしましょう。
- ターミナルで
Ctrl+Cを押してuvicornサーバーをシャットダウンします。 - サーバーを再起動します。
http://127.0.0.1:8000に再度アクセスします。
以前に公開した投稿がまだ存在することに気付くでしょう!フォーラムデータは現在PostgreSQLに保存されており、永続的なストレージが実現しました。
プロジェクトのオンラインデプロイ
最初のチュートリアルと同様に、このステップの結果をオンラインにデプロイして、友人たちにプロジェクトの変更と進捗を体験してもらうことができます。
簡単なデプロイソリューションはLeapcellを使用することです。
過去にデプロイしたことがある場合は、コードをGitリポジトリにプッシュするだけで、Leapcellが最新コードを自動的に再デプロイします。
Leapcellのデプロイメントサービスを初めて使用する場合は、この記事のチュートリアルを参照してください。
まとめ
このチュートリアルでは、フォーラムのバックエンドストレージを信頼性の低いインメモリリストから堅牢なPostgreSQLデータベースに正常に移行しました。
しかし、main.pyファイルに長いHTML文字列がたくさん含まれていて、コードの保守が困難になっていることに気付いたかもしれません。
次回の記事では、「テンプレートエンジン」の概念を導入し、Jinja2を使用してHTMLコードを独立したテンプレートファイルに分離し、フロントエンドコードの可読性と保守性を簡素化します。
Xでフォローする:@LeapcellJapan
関連記事: