この記事は何?
LLM での処理を行うプロキシ API をどう作るか
自分の失敗から私なりの考えをまとめた記事です
本記事の内容を一言で表すならば
本番で使われるデータのサイズや LLM 処理に要する時間を設計段階から意識し、最適なアーキテクチャを実装しよう
です
当たり前の話ですが、LLM の出力は再現性が低いこともあり私は引っかかりましたね
Q: 誰に向けた記事?
A: LLM処理をプロダクトに取り入れたい方々に向けて書きました!
LLM に処理の一部を担わせるプロキシ API の設計思想
みなさんは Requests body を OpenAI や Claude, Gemini 等の AI に流し込み、返り値をクライアントに返すプロキシ API を作成する際、どのように設計しますか?
まずは下記のようなアーキテクチャを想像するのではないでしょうか
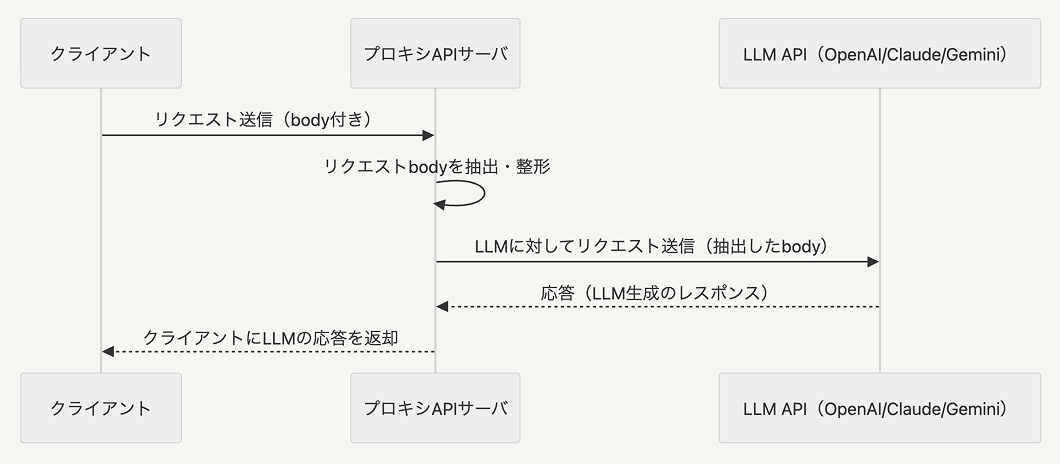
LLM にアクセスするための API キーの漏洩を防いだり、LLMOps を回すためにデータをストレージに送ったりと、プロキシ API を必要とするケースは多いはずです
私の失敗
多くの MVP 開発において、上図の構成で事足りると思います
しかし、上記の構成ではうまくいかない場合もあります
それは LLM 処理に時間がかかる場合やプロキシ API に送られた body の中身がデカすぎる場合です
AWS Lambda でプロキシ API を実装するケースを考えてみましょう
よくあるケースは LLM 処理が長すぎて API Gateway 側で30秒タイムアウトが発生する場合です
API 実装初期は数秒でレスポンスが返ってきていたので安心して開発を進めていたが、本番データが予想よりもデカく、処理に30秒以上かかることが判明しました
どうすればよかったのか?
「入力として想定されるデータとして、一番サイズが大きいケースは何か」これを最初に考えるクセをつけよう
タイムアウトの懸念があるなら非同期処理で実装しよう
入力値の上限ギリギリを攻めて開発に着手しましょう
また、データがなくともテストせずともタイムアウトを予期できるケースがあります
それはリストの要素一件一件に対して LLM 処理を実行する場合です
こちらはリストの要素数が多すぎる場合には簡単にタイムアウトしてしまいます(逐次実行の場合)
このようなケースでは Lambda ではなく AWS StepFunction や他のアーキテクチャを使用しましょう
非同期処理に切り替えることでタイムアウト問題を乗り越えられます
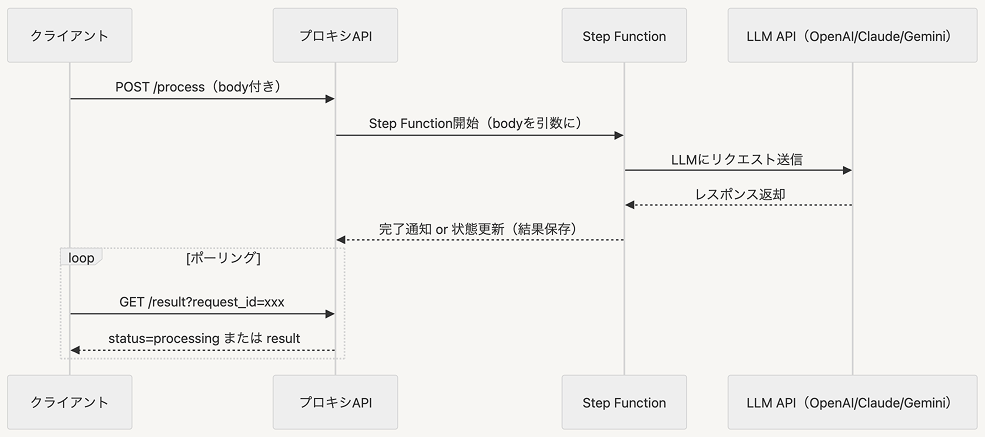
StepFunction を使うと作成するリソースを最小限に抑えることができるため、管理が楽になります
しかし、StepFunction でも受け付けられないパターンもあります
それはリクエストサイズが1MB を超える場合です
StepFuncrion のリクエストサイズ上限が1MB であるため、このようなケースでは SQS と DynamoDB を使うことで対応しましょう
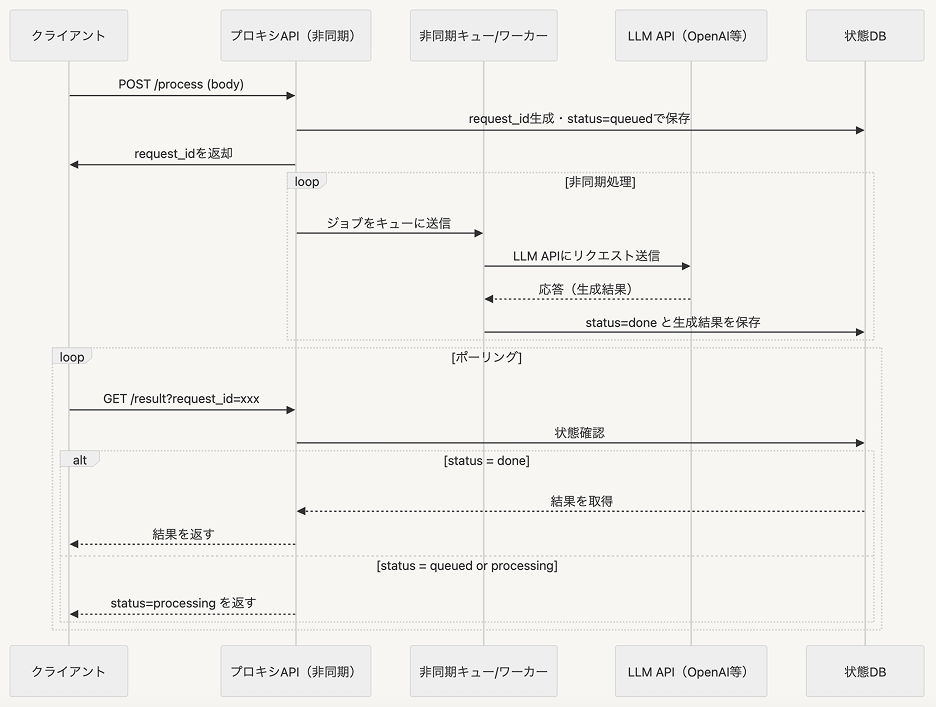
SQS で LLM 処理をバッチで実行し DynamoDB に送り、ポーリングで DynamoDB から処理結果を取り出す方法です
おわりに
本記事では LLM に処理の一部を担わせるプロキシ API の設計思想について書きました
AWS を例に挙げて書きましたが、GCP や Cloudflare でも同じ考え方でアーキテクチャを組めるはずです!
ここまで読んでいただきありがとうございました🙌